분산 데이터베이스와 분산 원장 (1)
READ ME
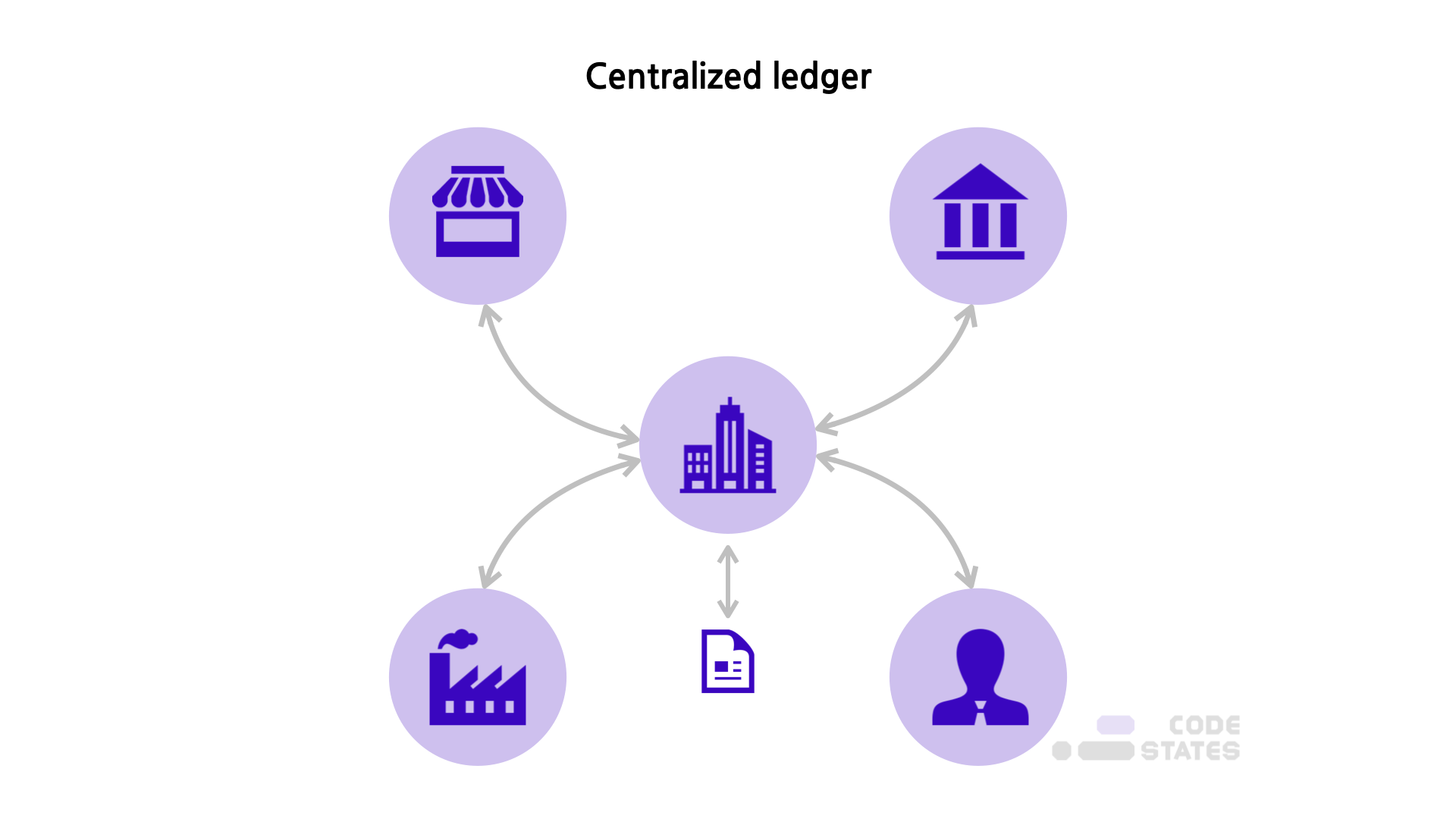
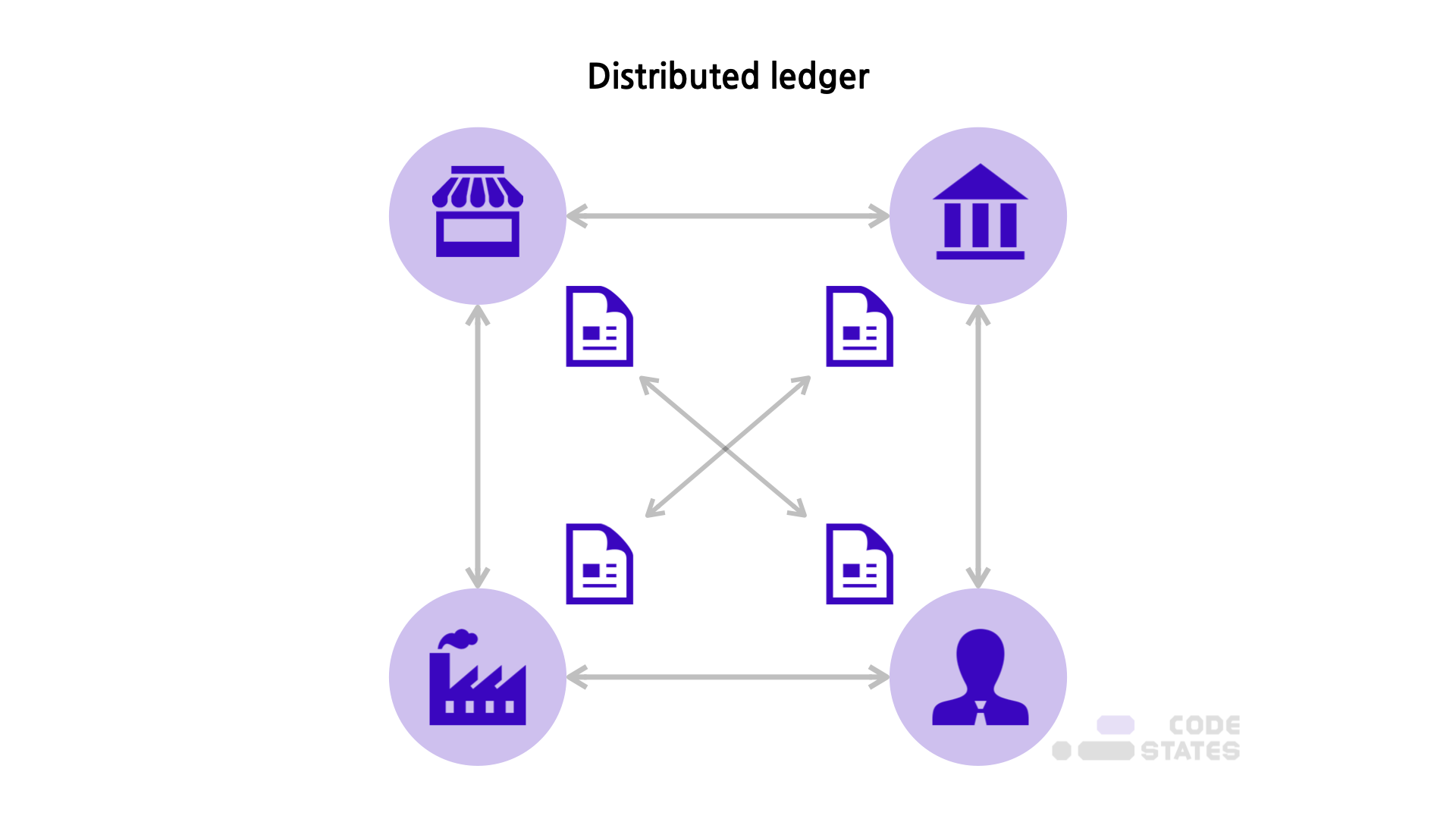
블록체인은 P2P(Peer to Peer) 네트워크를 통해 관리되는 분산 데이터베이스의 한 종류이다. 따라서 거래 정보를 담은 장부를 중앙 서버 한 곳에 저장하는 대신, 블록체인 네트워크에 연결된 여러 컴퓨터에 저장 및 보관한다.
블록체인은 제3의 신용기관 없이도 네트워크 참여자들 간의 신뢰할 수 있는 거래가 가능하게 함으로써 디지털 인프라에 탈중앙화, 수평적인 디지털 비즈니스의 기반이 된다. 그렇기에 다양한 산업 분야(IT, 금융, 정부, 언론, 의료, 법률 등)에 쓰일 수 있는 잠재력이 있다.
분산 데이터베이스란?
들어가며
먼저 분산 원장 기술의 기초가 되는 분산 데이터베이스(Distributed Database)에 대해서 알아보겠다.
혹자는 “분산 데이터베이스와 블록체인이 같은 것이 아니냐, 이름만 바꿔 포장한 것이 아니냐?” 의혹을 제기하기도 한다.
분산 데이터베이스란?
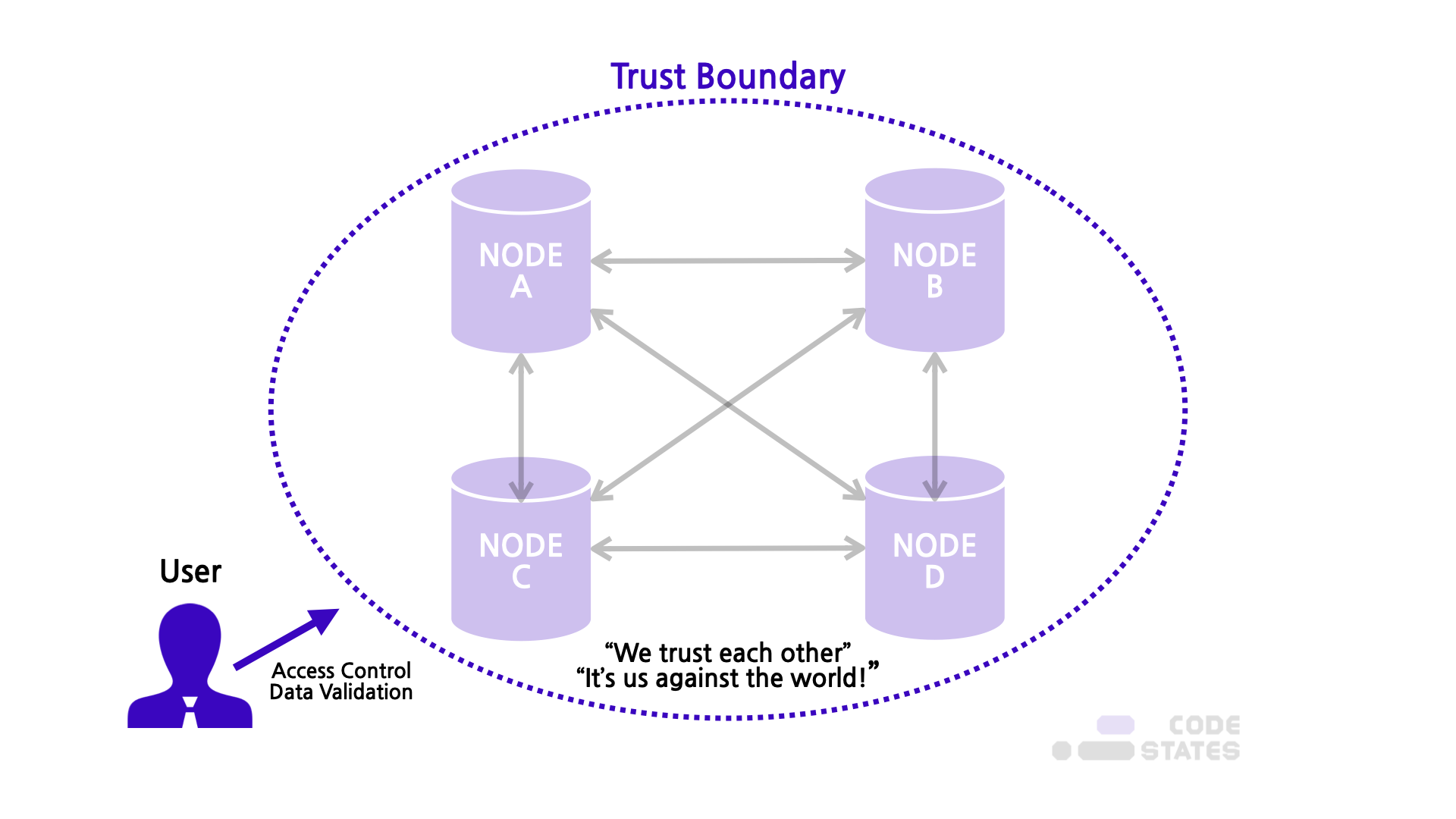
분산 데이터베이스는 하나의 데이터베이스 관리 시스템(DBMS, Database Management System)으로, 여러 CPU에 연결된 저장장치들을 제어하는 형태의 데이터베이스이다.
물리적으로 여러 위치에 분산 저장하고 흩어져 있는 시스템이지만, 논리적으로는 하나인 것처럼 활용한다는 것이 핵심 개념이다.
즉 데이터베이스에 접근하는 사용자 입장에서는 마치 하나의 데이터베이스에 접근하는 것과 다르지 않다.
물리적으로 떨어져 있는 저장소, 즉 노드들은 네트워크를 통해 연결된다. 이 노드들은 투명성 확보가 가장 중요하다. 목표로 하는 투명성은 총 6가지로써, 아래와 같다.
| 종류 | 내용 | 특징 |
|---|---|---|
| 병행 | 다수의 트랜잭션 수행 시 결과가 일관성 유지 | 자원처리 양 및 속도 개선 |
| 장애 | 장애 발생이 All or Nothing 유지 (원자성 유지) | 데이터 일관성 |
| 지역사상 | 개별 지역의 물리적 이름과 관계 없이 접근 가능 | 확장성 확보 |
| 위치 | 데이터를 물리적 저장 위치가 아닌 논리적 입장에서 접근 | 생산성, 활용성 강화 |
| 중복 | 데이터를 지역별로 중복으로 저장하여도 데이터 처리 가능 | 병목 현상 해소 |
| 분할 | 물리적 구조가 여러 단편으로 분할 저장되어 논리적 사용 | 성능 향상 |
분산 데이터베이스의 대표적 기술
분산 데이터베이스의 대표적 기술
데이터베이스를 물리적으로 여러 개로 만들고 관리하기 위한 기술은 대표적으로 3가지가 있다.
- 클러스터링
- 레플리케이션
- 샤딩
이 기술들의 특징에 대해 간단하게 알아보겠다.
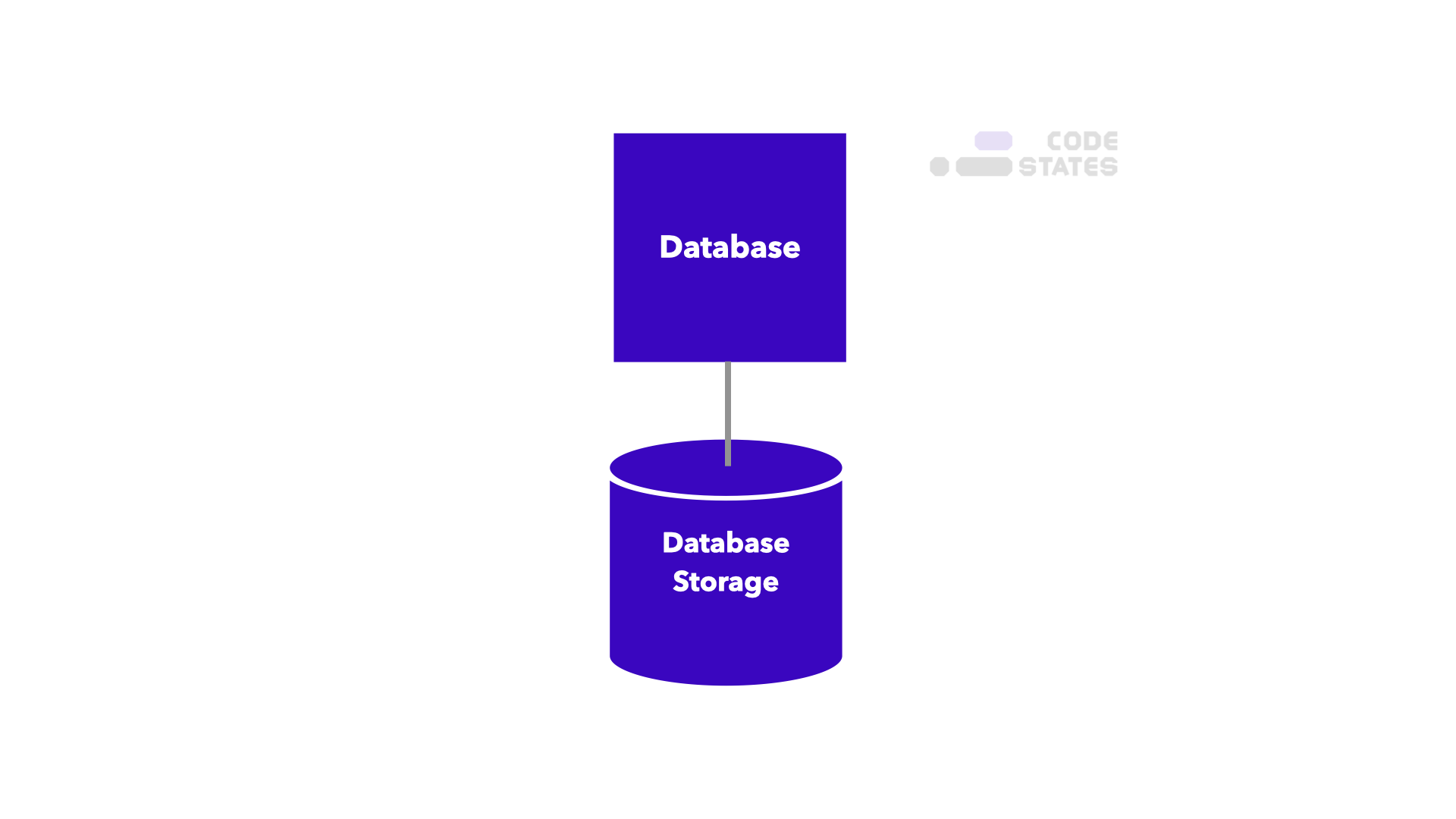
일반적인 데이터베이스를 간단하게 도식화하면 이와 같다. 데이터 요청을 처리하는 서버, 실제 데이터를 저장하는 스토리지가 각 1개씩 있다.
클러스터링
배경:
Q: 데이터베이스 서버가 죽으면 어떻게 할까? A: 서버를 여러 개로 만들자!
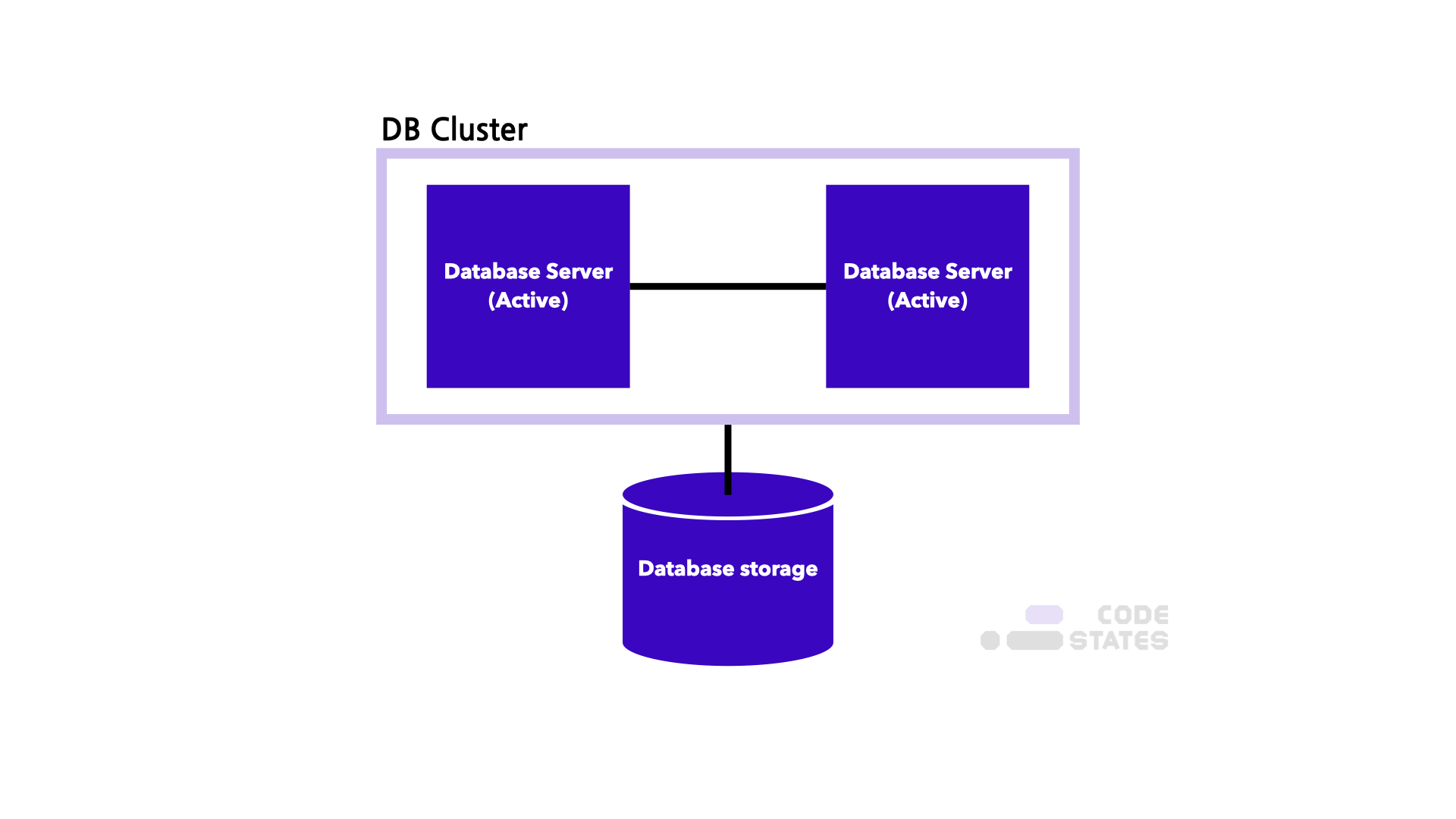 Active-Active는 클러스터를 항상 가동하여 가용할 수 있는 상태로 두는 구성 방식
Active-Active는 클러스터를 항상 가동하여 가용할 수 있는 상태로 두는 구성 방식
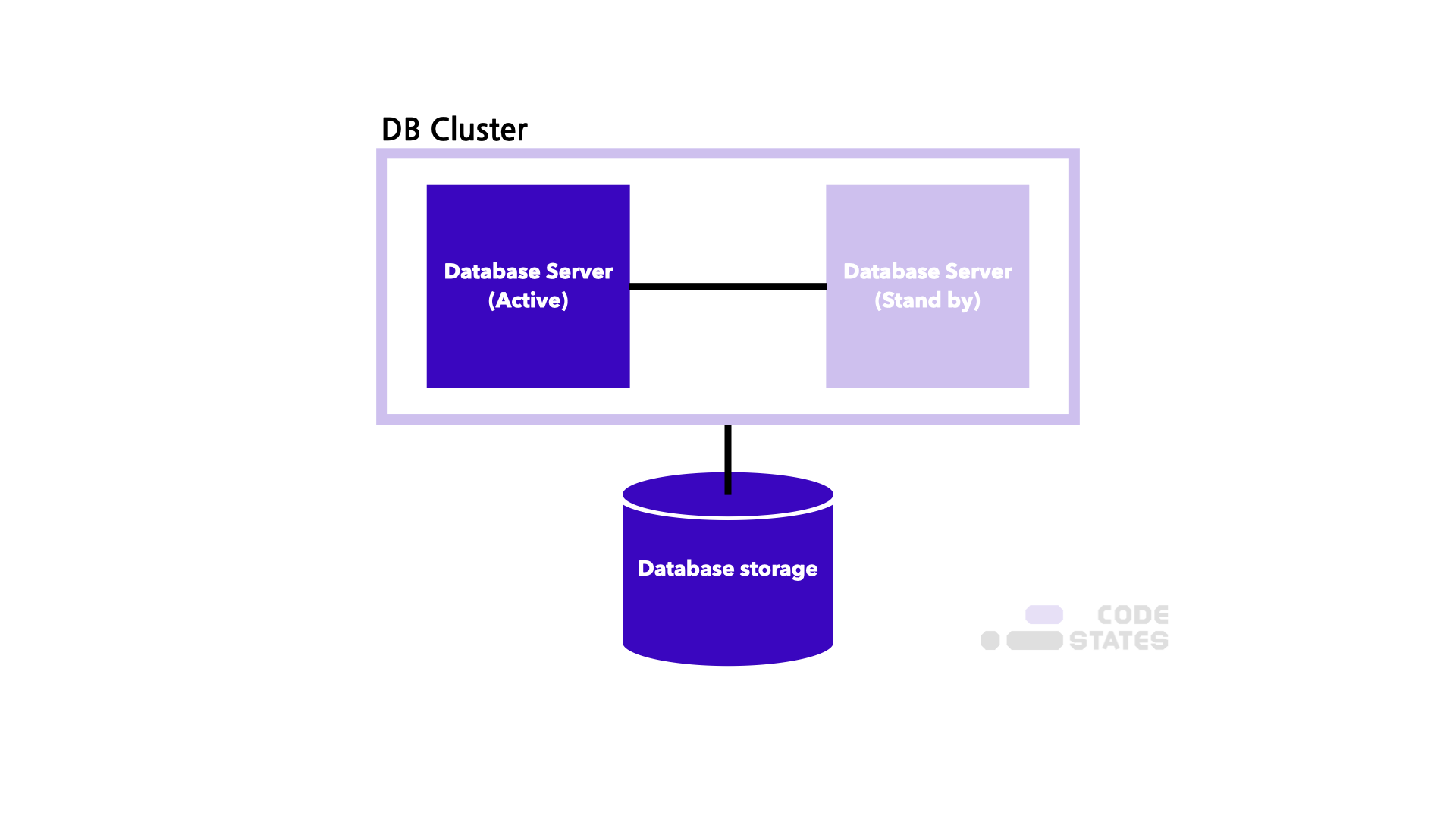 Active-Standby는 일부 클러스터는 가동하고, 일부 클러스터는 대기 상태로 구성하는 방식
Active-Standby는 일부 클러스터는 가동하고, 일부 클러스터는 대기 상태로 구성하는 방식
- 장점
- 데이터베이스 서버 하나가 죽어도 다른 서버가 역하을 대신할 수 있어서 지속 서비스 제공 가능
- 서버가 여러 대이기 때문에 성능적으로 유리함
- 단점
- 데이터베이스는 1개이기에 병목이 생길 수 있음
- 서버 여러 대를 동시에 운영해야 하므로 비용이 많이 들어감
레플리케이션
**배경: **
Q: 저장된 데이터가 손실되면 어떻게 할까? A: 데이터베이스 스토리지도 여러 개로 하자!
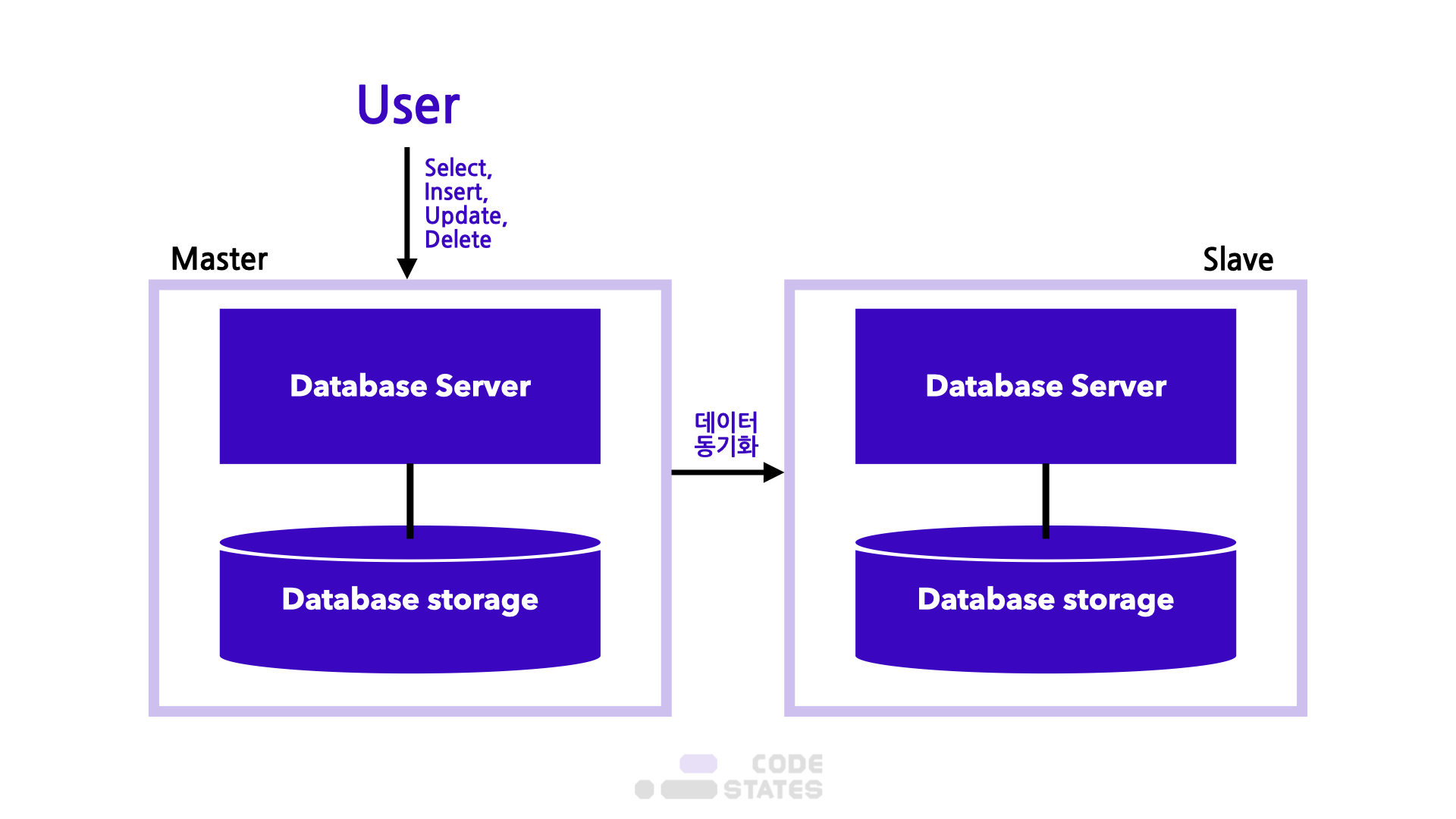 단순 백업 방식
단순 백업 방식 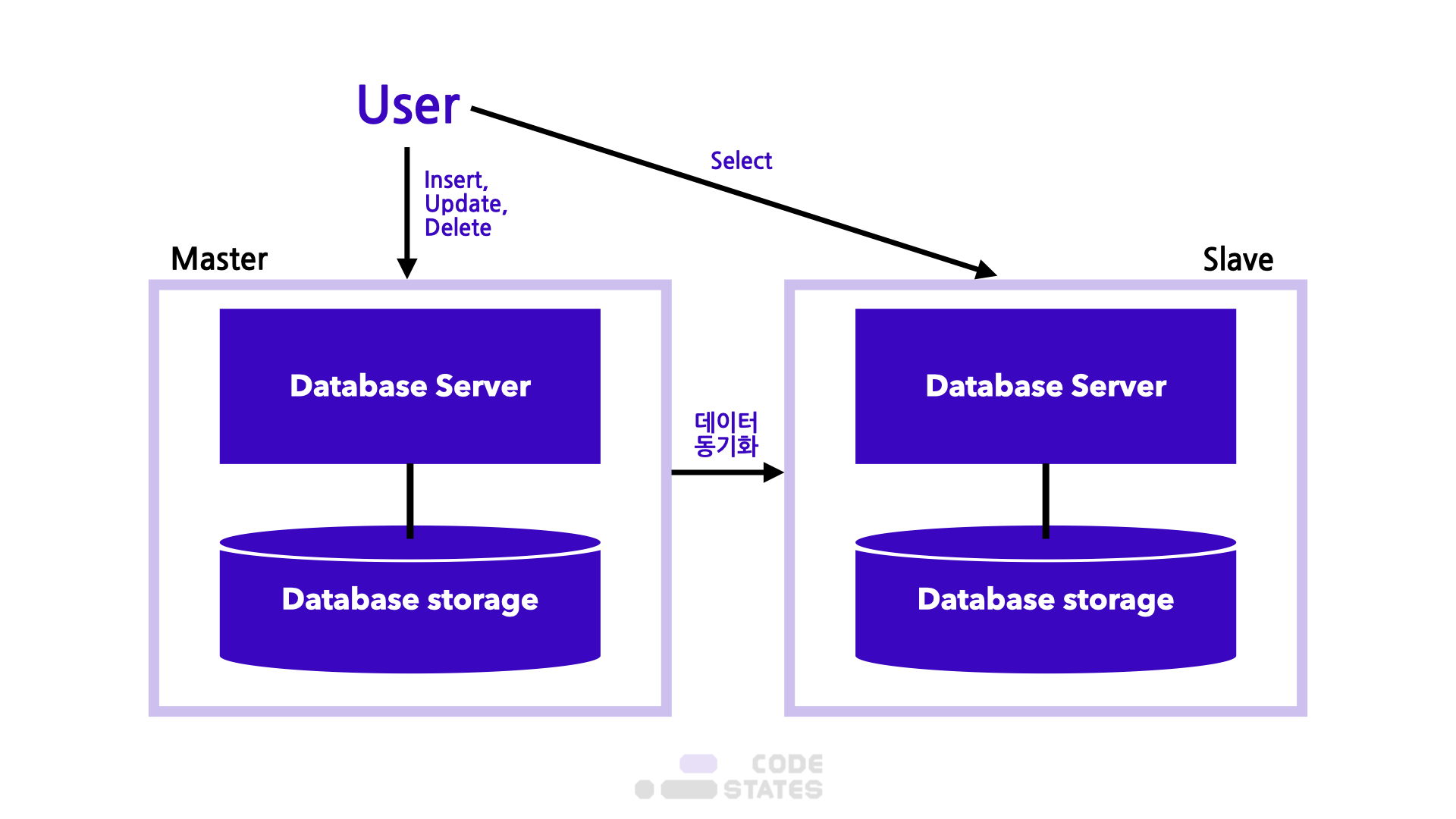 부하 분산 방식 Slave에는 Read만 가능
부하 분산 방식 Slave에는 Read만 가능
- 장점
- 데이터베이스 Read(Select) 성능을 높일 수 있음
- 비동기 방식으로 운영되어 지연 시간이 거의 없음
- 단점
- 각 노드 간의 데이터 동기화 보장이 어려움
- Master 노드가 다운되면 복구 및 대처가 어려움
샤딩
**배경: ** Q: 데이터가 너무 많아서 검색 성능이 좋지 않은데 이를 더 빠르게 못할까? A: 테이블을 나누어서 저장하자!
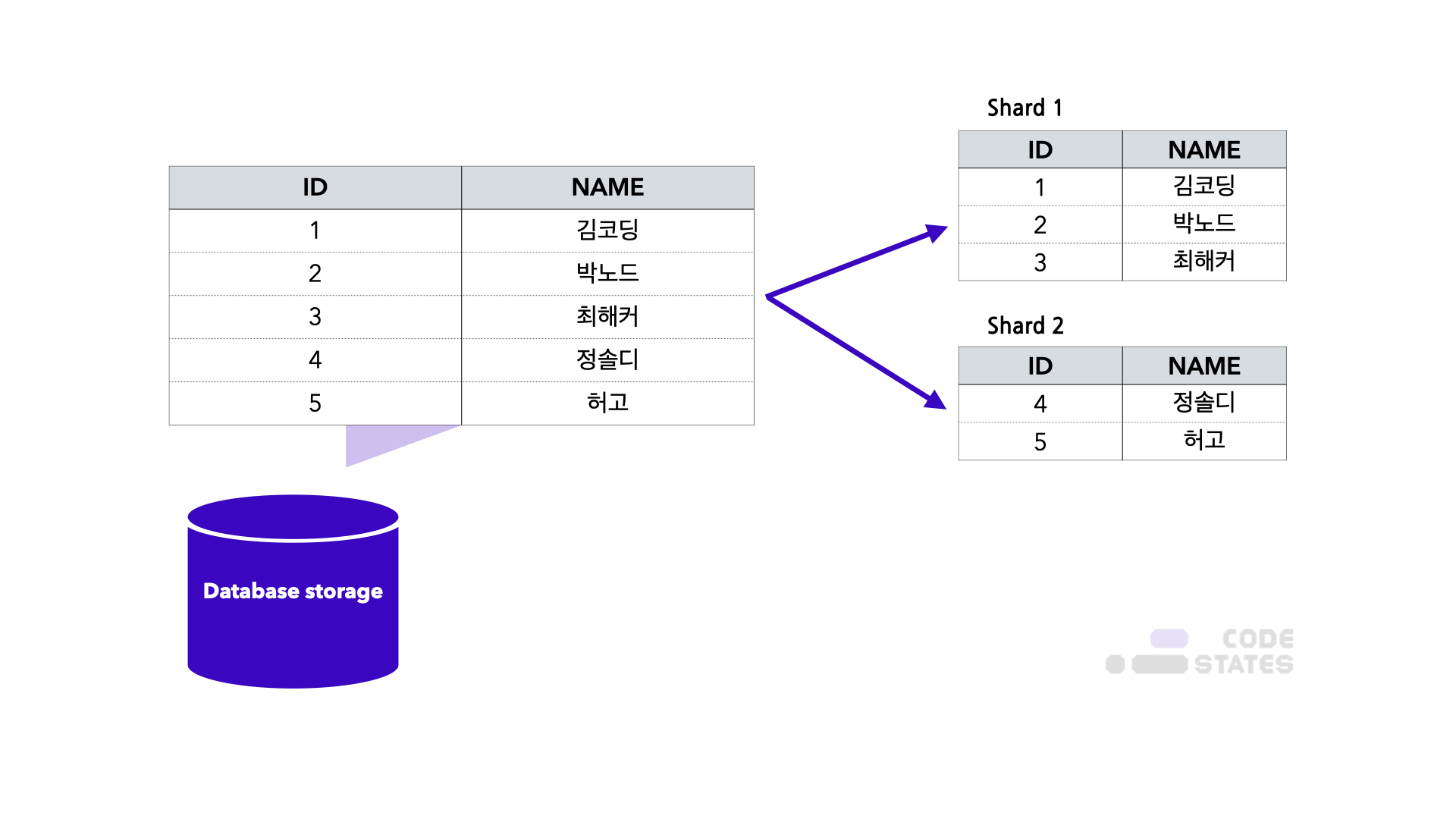 테이블을 로우 단위로 나누어서 각각의 샤드로 저장
테이블을 로우 단위로 나누어서 각각의 샤드로 저장
- 장점
- 서버의 수평적 확장이 가능함
- 스캔 범위를 줄여주기 때문에 데이터 질의(쿼리) 반응 속도가 빨라짐
- 단점
- 데이터를 적절히 분리하지 못하면 오히려 샤딩 전보다 비효율적일 수 있음
- 한 번 분할되면 이전으로 다시 합치기 어려움
이때 데이터를 보다 잘 분산시키는 것이 중요한데, 이를 위해 Shard key를 통해 나눠진 샤드 중 어떤 샤드를 결정할지를 정한다.
해당 Shard key 결정 방식에 따라서 샤딩 방법 역시 나뉜다.
해시 샤딩
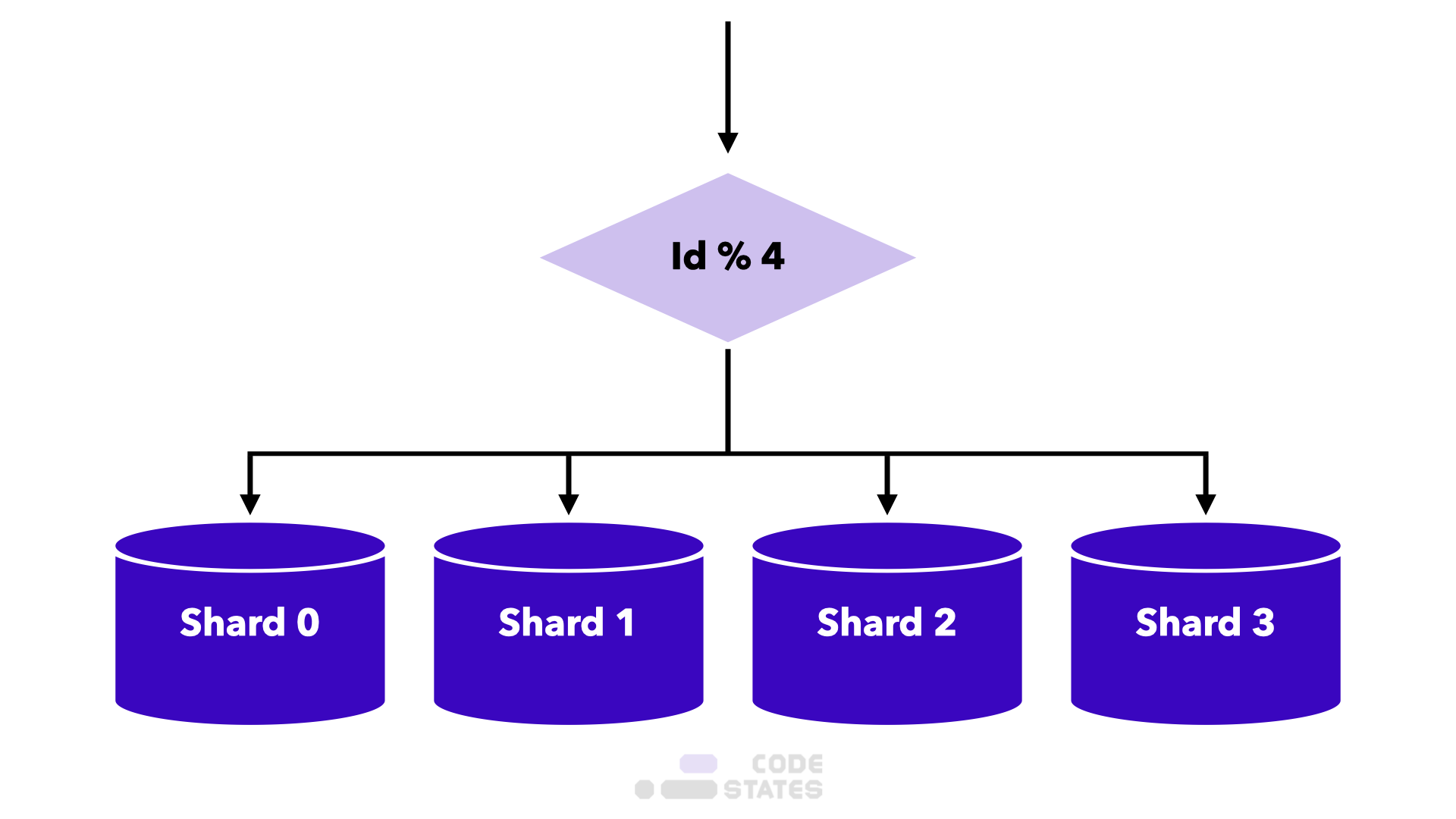 해시 함수를 사용해 Shard key를 나누는 방식
해시 함수를 사용해 Shard key를 나누는 방식- 장점
- 샤드에 수만큼 해싱하면 되기에 구현이 간단함(해시 함수를 사용해 Shard key를 나누는 방식)
- 단점
- 샤드가 늘어나면 해시 함수가 달라져야 하기에 확장성이 떨어짐
- 단순히 해시 함수를 통해 나누기에 각 샤드 별 공간에 대한 효율을 고려하지 않음
- 장점
다이내믹 샤딩
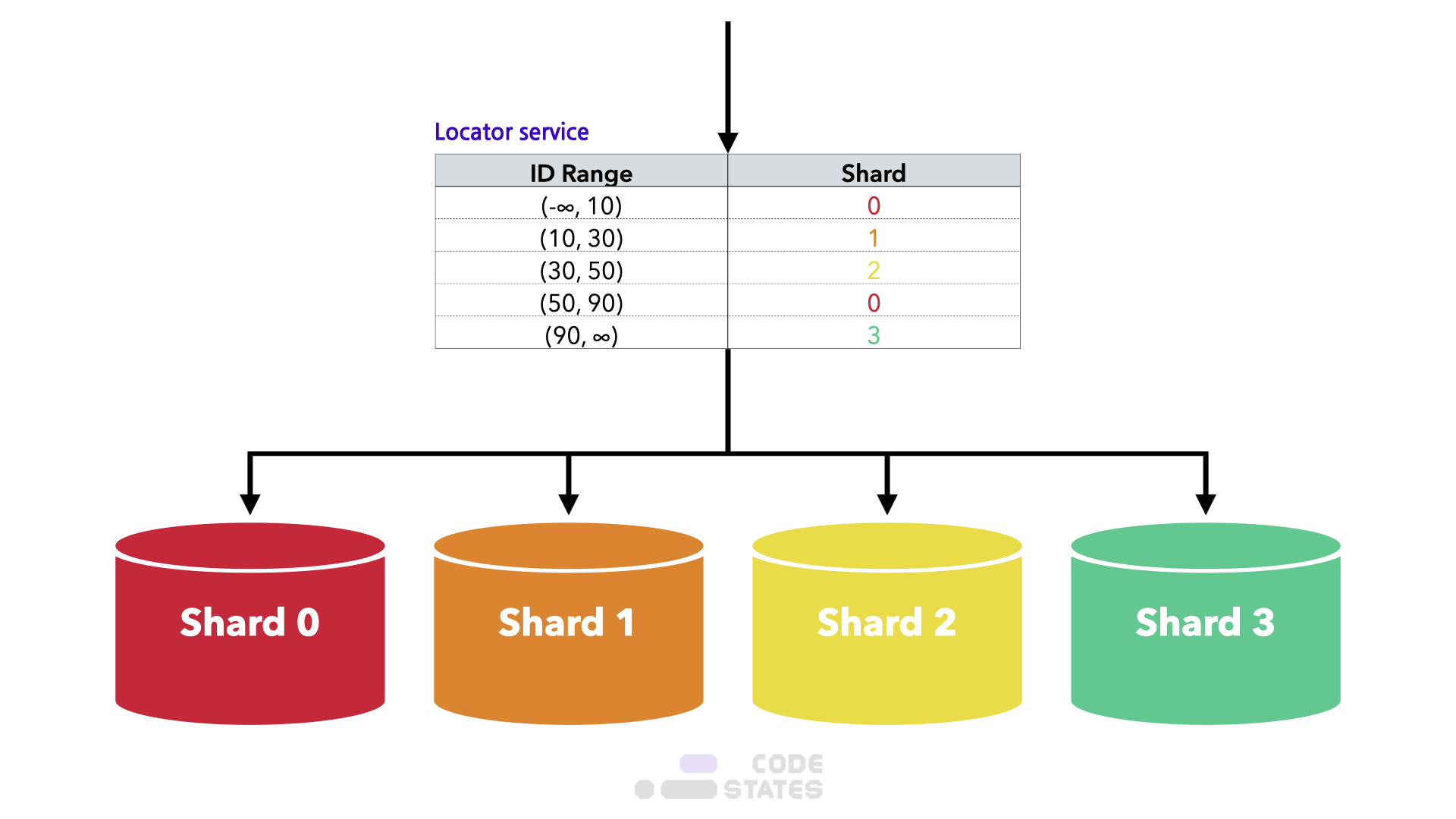 Locator service라는 테이블 구성 요소를 통해 Shard key 구성
Locator service라는 테이블 구성 요소를 통해 Shard key 구성- 장점
- 샤드가 하나 더 추가되면 Locator service에 Shard key를 추가하는 방식으로 확장성 유연함
- 단점
- 데이터를 재배치 시 Locator service 역시 동기화 요구됨
- Locator service에 의존적이라 해당 테이블에 문제가 생기면 데이터베이스에도 문제가 전이됨
- 장점
엔티티 그룹 샤딩
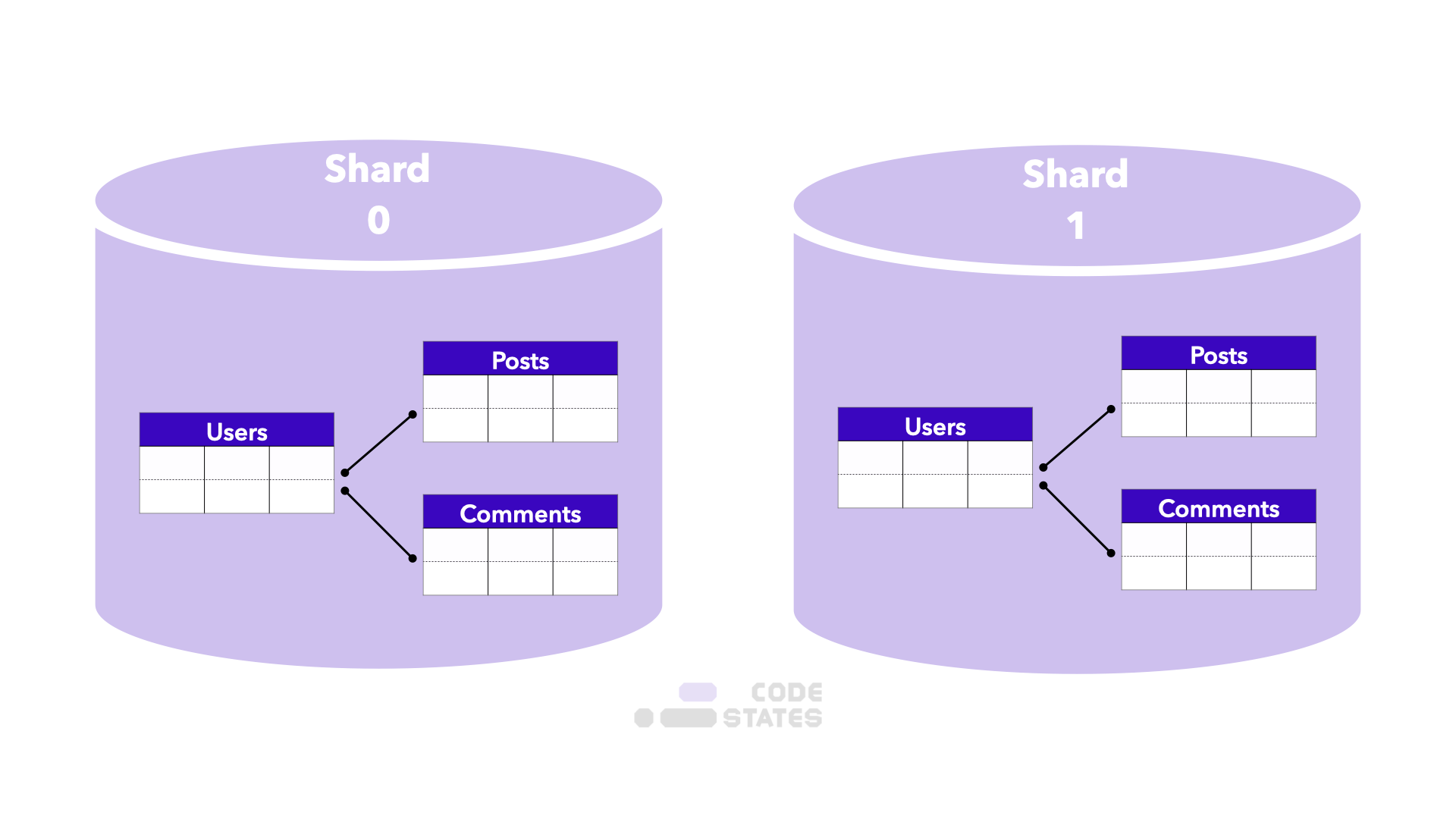 관계되어 있는 엔티티끼리 같은 샤드 내에 공유
관계되어 있는 엔티티끼리 같은 샤드 내에 공유- 장점
- 단일 샤드 내에서 데이터 질의(쿼리)가 효율적
- 단일 샤드 내에서 강한 응집도 가짐
- 단점
- 다른 샤드의 엔티티와 연광이 되는 데이터 질의(쿼리)의 경우 실행 효율 떨어짐
- 장점
